Teil 1: Einführung in Deep Learning
Dieser Artikel unserer Blog-Reihe behandelt das Thema Deep Learning und stellt einen Bezug zu dem vorherigen Artikel zum Thema Machine Learning und künstliche Intelligenz (KI) her. Insbesondere wird dabei auf die Techniken und Möglichkeiten eingegangen, die der Einsatz von Deep Learning-Modellen gerade in Hinblick auf E-Mail-Sicherheit bietet.
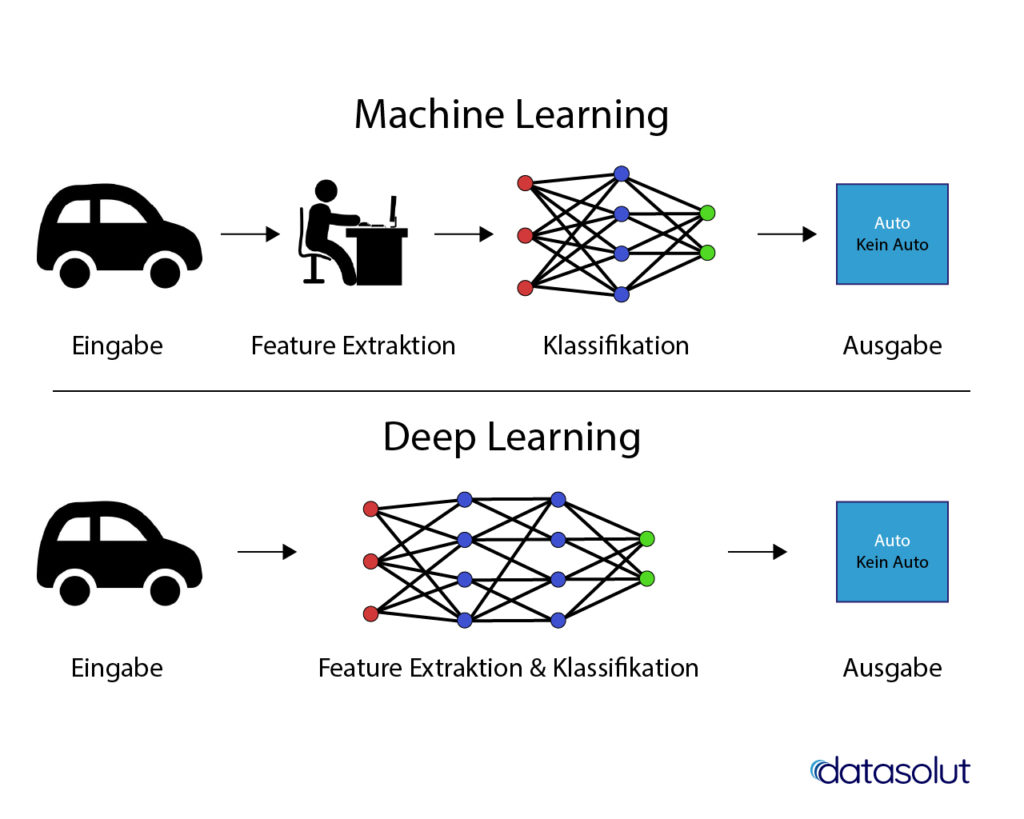
Deep Learning ist ein Teilgebiet des Machine Learning und basiert auf künstlichen neuronalen Netzwerken (neural networks), die aus Knoten und gewichteten Verbindungen zwischen den Knoten bestehen. Dies ist ähnlich zu Neuronen und Synapsen in einem biologischen Gehirn. Deep Learning stellt einen Paradigmenwechsel in der Art und Weise dar, wie AI-Systeme lernen und Daten verarbeiten, indem AI in die Lage versetzt wird, große Datenmengen selbstständig zu strukturieren und Muster zu erkennen. Im Gegensatz zu herkömmlichen Ansätzen des Machine Learning, die auf vorgefertigten Daten beruhen, deren wichtige Merkmale häufig per Feature-Extraktion von Menschen ausgewählt werden, lernen Deep Learning-Algorithmen selbständig aus Rohdaten. Dies ermöglicht flexible, skalierbare models, die leicht für andere Zwecke eingesetzt werden können.
Einsatz künstlicher neuronaler Netzwerke
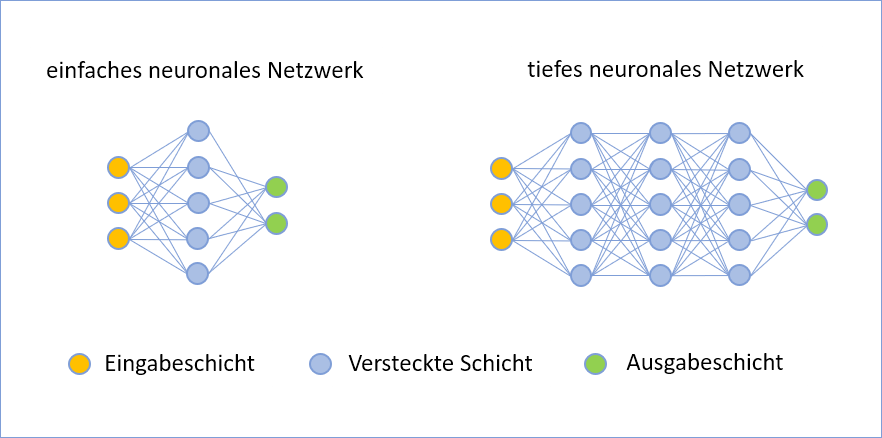
Deep Learning-Algorithmen setzen für die Extraktion und Analyse der Daten künstliche neuronale Netzwerke ein. Bei einem künstlichen neuronalen Netz sind die Knoten in verschiedenen Schichten (layers) angeordnet. Außer einer Eingabeschicht für die Aufnahme der Daten und einer Ausgabeschicht für die Darstellung des Ergebnisses gibt es eine oder mehrere Zwischenschichten (Hidden Layers). Neben der automatisierten Extraktion relevanter Eigenschaften der Daten ist die Tiefe des verwendeten neural networks ein weiteres wichtiges Unterscheidungsmerkmal von Deep Learning zu klassischen Machine Learning-Algorithmen.
Neuronale Netze können dabei auch für Algorithmen eingesetzt werden, die nicht dem Deep Learning, sondern dem herkömmlichen Machine Learning zuzuordnen sind, beispielsweise mittels überwachten Lernens. So könnten beispielsweise für die Einordnung von E-Mails als Spam bzw. kein Spam bestimmte Daten aus der E-Mail (wie Absender, Anrede, Inhalte) in ein neuronales network gegeben werden. Dieses trifft eine Vorhersage, welche wieder anhand der vorher vorgenommenen Einordnung überprüft wird. Sowohl die Auswahl der Eingabedaten als auch die Einordnung der Daten werden dabei von Menschen durchgeführt. Das dabei eingesetzte neuronale Netz besteht maximal aus einer Eingabe-, einer Ausgabe- und einer versteckten Schicht.
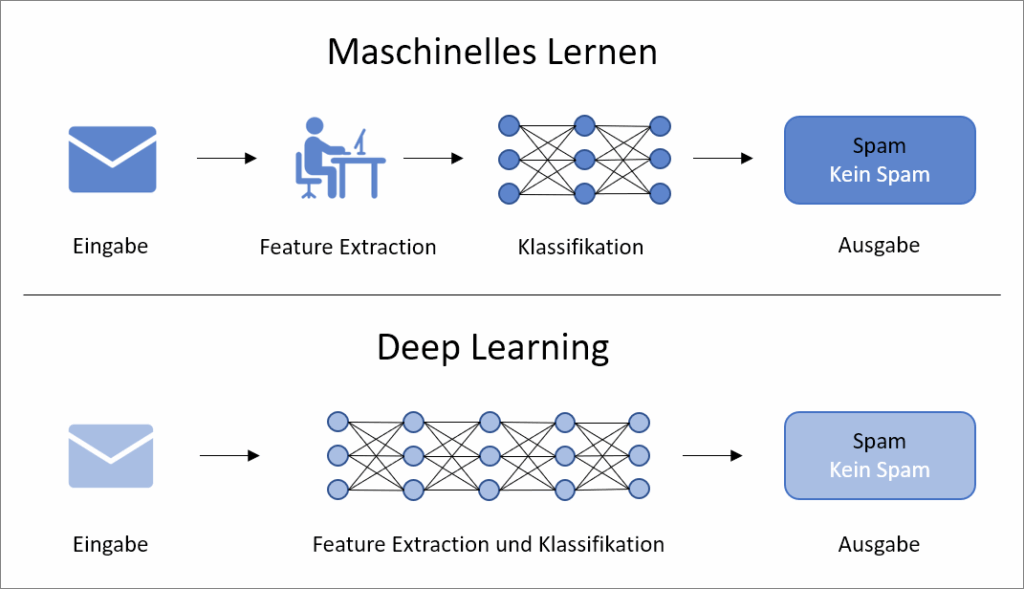
In Anlehnung an: https://datasolut.com/wp-content/uploads/2020/03/machine-learning-vs-deep-learning-1024×819.jpg
Deep Learning hingegen arbeitet mit tiefen neuronalen Netzen. Diese bestehen neben der Ein- und Ausgabeschicht aus mindestens zwei Zwischenschichten. Die Anzahl der Zwischenschichten ist bei den meisten Deep Learning-Modellen jedoch wesentlich höher. Ein weiterer Unterschied besteht in der automatisierten Verarbeitung der Eingabedaten. So würden für die Erkennung von Spam-E-Mails alle Rohdaten der E-Mail als Eingabe verwendet werden, mit denen das tiefe neural network trainiert wird. Der Deep Learning-Algorithmus findet dabei selbständig Strukturen in den Daten. Die erzeugte Ausgabe kann dann mittels Fehlerrückführung benutzt werden, um das Netzwerk zu trainieren.
Eigenschaften von Deep Learning-Modellen
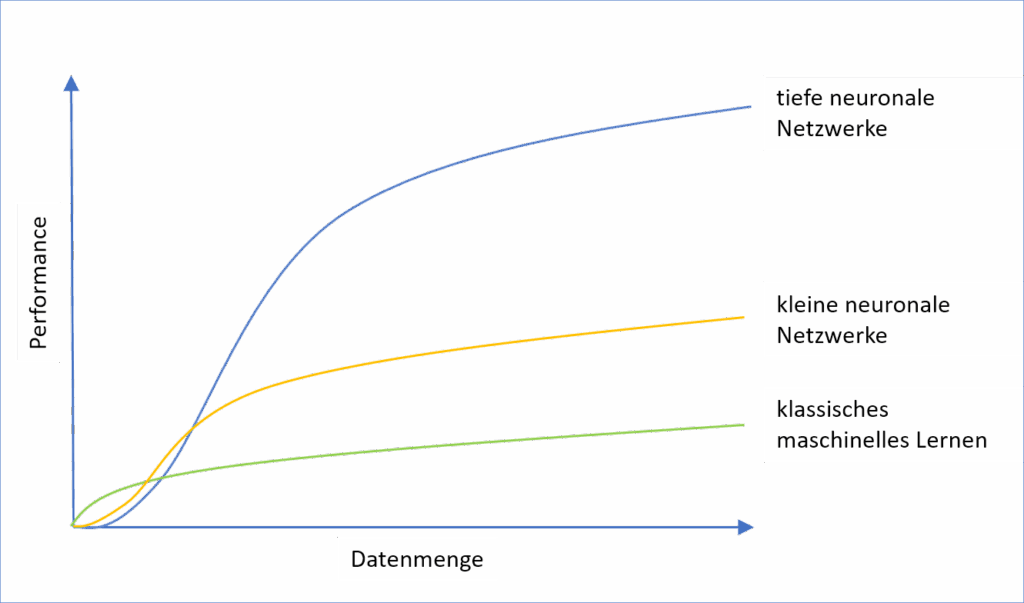
Hieraus ergeben sich verschiedene Einsatzgebiete für klassisches Machine Learning und Deep Learning. Gerade wenn große, unstrukturierte Datenmengen verarbeitet werden müssen, wie beim autonomen Fahren, der Interpretation von Texten oder die Verarbeitung beliebiger E-Mails mit unbekannter Struktur und Inhalt, bietet Deep Learning Vorteile. Voraussetzung dafür ist eine längere Trainingszeit und leistungsstärkere Computer. Das ist auch der Grund, weshalb Deep Learning erst in den letzten zwei Jahrzehnten praktisch an Bedeutung gewonnen hat, obwohl erste Überlegungen und Theorien dazu schon seit den 1940er Jahren unternommen wurden. Auch ist eine größere Datenmenge zum Trainieren des Deep Learning-Algorithmus notwendig, als dies bei herkömmlichen Verfahren des Machine Learning erforderlich ist.
| Maschinelles Lernen | Deep Learning | |
| Struktur der Eingabedaten | strukturiert | strukturiert und unstrukturiert |
| Menge der Eingabedaten | klein – mittel | groß (Big Data) |
| Hardware | einfache Hardware | leistungsstarke Computer (mit GPUs). |
| Aufbereitung der Eingabedaten | Merkmale müssen verstanden und Daten aufbereitet werden | keine Aufbereitung der Daten notwendig (Raw Data) |
| Trainingszeit | relativ kurz – Stunden | Wochen bis Monate |
| Interpretierbarkeit | einige Algorithmen sind leicht zu interpretieren (z.B. Entscheidungsbäume) | oft unmöglich zu interpretieren |
siehe: https://datasolut.com/was-ist-deep-learning/
Skalierbarkeit
Ein weiterer wichtiger Aspekt tiefer neuronaler Netzwerke ist deren Skalierbarkeit. So können Deep Learning-Algorithmen für die Erkennung natürlicher Sprache (NLP) eingesetzt werden. Diese AI-Algorithmen werden trainiert, um den Inhalt und die Bedeutung von Texten zu verstehen. Beispielsweise können sie Hinweise erkennen, ob eine Phishing-Mail vorliegt. Das NLP-Model kann erkennen, ob der Inhalt der E-Mail dem Empfänger eine Dringlichkeit suggeriert. Auch kann der Inhalt eines eventuell vorhandenen E-Mail-Anhangs in einer Sandbox untersucht werden. Ein schon vorhandenes NLP-Model kann auch in diesem Kontext weiter trainiert werden, um die Genauigkeit zu erhöhen.
Zusammenfassend lässt sich feststellen, dass tiefe neuronale Netze erfolgreich sind, wenn sie aus den Eingabedaten ohne vorherige Bearbeitung selbständig Strukturen erkennen können. Da auch Ähnlichkeiten zwischen den erlernten Strukturen und den für die Lernaufgabe passenden Mustern selbstständig erkannt werden, ergibt sich eine Reduktion der Komplexität der Daten. Da das Model von der Eingabe der Rohdaten bis zur Ausgabe trainiert wird, wird auch von einem Ende-zu-Ende-Lernen gesprochen. Gerade bei großen, unstrukturierten Datenmengen bieten tiefe neuronale Netze Vorteile und führen in der Regel zu besseren Ergebnissen.
Teil 2: Architekturen von neuronalen Netzwerken
In diesem zweiten Teil von Deep Learning werden einige Typen tiefer neuronaler networks vorgestellt und untersucht, wie diese im Zusammenhang mit E-Mail-Sicherheit anwendbar sind.
(Frauenhofer Gesellschaft – Publikation Maschinelles Lernen)
Deep Feedforward Network
Bei dieser Architektur werden die Signale von der Eingabe zur Ausgabe über Schichten von neurons verarbeitet (Feedforward). Gewichte an den Verbindungen zwischen den neurons stellen die Stärke der Signalübertragung dar. Bei tiefen Feedforward networks sind eine Vielzahl von Zwischenschichten vorhanden. Durch Fehlerrückführung, d. h. durch Rückmeldung eines Fehlers im Ergebnis an das Netzwerk, können die Gewichte abgestimmt und das Ergebnis optimiert werden.
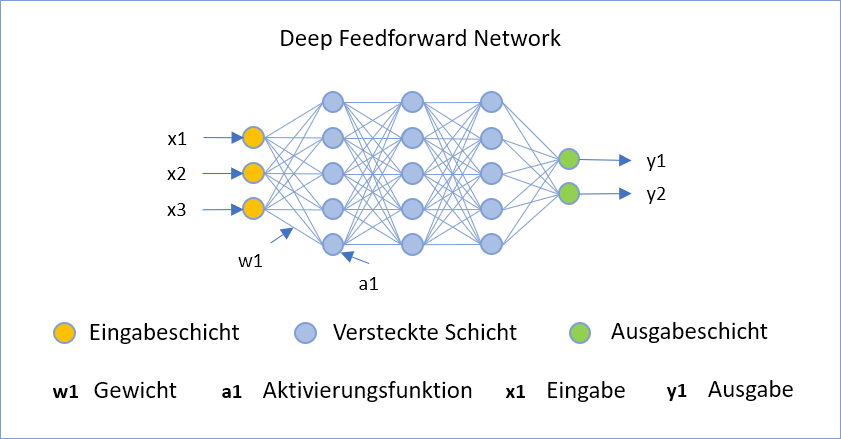
Typische Einsatzgebiete für solche networks sind Klassifikations- und Regressionsaufgaben. Im Bereich der E-Mail-Sicherheit gehört dazu die Einteilung von E-Mails in die Kategorien Spam/kein Spam.
Convolutional Neural Network (CNN)
Mit Hilfe eines solchen tiefen neuronalen networks können durch mathematische Operationen spezielle lokale Merkmale erkannt werden, die in den Eingabedaten an unterschiedlichen Stellen auftreten können. So wird die Menge der Eingabedaten komprimiert und nur wesentliche Merkmale verarbeitet.
Ein denkbares Einsatzszenario für ein CNN ist z. B. die Erkennung von Malware in einem lokalen Netzwerk einer Firma. Das network kann aus den Daten des lokalen Netzwerks für Malware typische Muster erkennen und so das Schadprogramm identifizieren.
Transformer Architektur
Die Transformer-Architektur ist in den letzten Jahren im Bereich Deep Learning und tiefe neuronale networks immer populärer geworden. Mit der Transformer-Architektur können sequentielle Daten auch parallel verarbeitet werden. Damit bilden sie die Grundlage für Large Language Models (LLMs) wie ChatGPT, die natürliche Sprache verarbeiten. Transformer-Models können Inhalte von E-Mails analysieren und Tendenzen in der Aussage erkennen, die den Empfänger zu bestimmten Handlungen verleiten.
Generative Adversarial Network (GAN)
Bei dieser Architektur werden zwei neuronale networks parallel eingesetzt. Ein Generator wird trainiert, um Trainingsdaten zu erzeugen. Diese Daten werden zusammen mit realen Daten dem Diskriminator gegeben, der die Entscheidungsfindung ausführt. Das Ergebnis beeinflusst wiederum das Training des Generators, wodurch bessere Beispiele erzeugt werden.
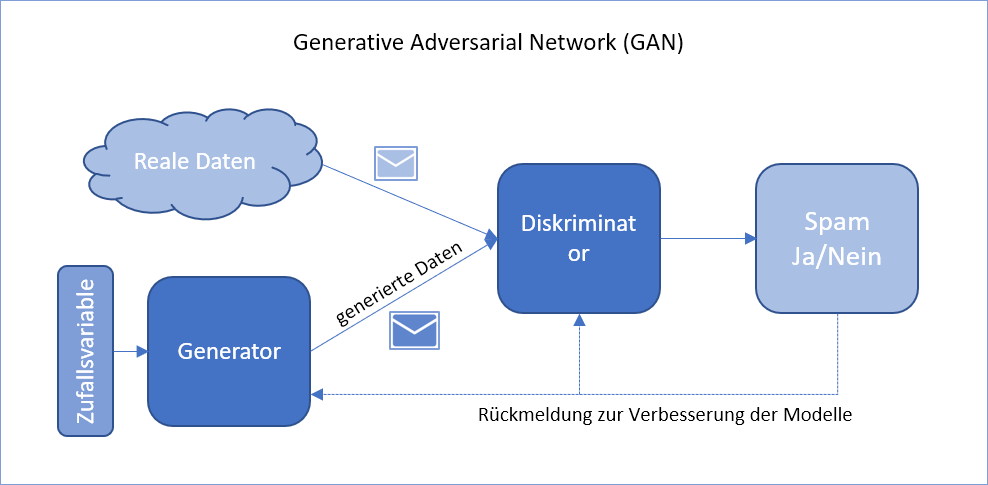
Im Bereich E-Mail-Sicherheit können GANs realistische Angriffsszenarien generieren, um die Wirksamkeit von Spam- und Phishing-Erkennungssystemen zu verbessern. Auch für neu auftretende Formen von Schadmails kann das GAN schnell trainiert werden.
Neben den hier genannten Formen gibt es noch viele verschiedene models tiefer neuronaler Netze, die für Deep Learning verwendet werden. Auch Mischformen verschiedener networks werden dabei eingesetzt.
Teil 3: Herausforderungen und Grenzen von Deep Learning
In diesen dritten Teil erfolgt eine Bewertung der aktuellen Entwicklung von Deep Learning hinsichtlich der Kriterien wie Datenqualität, Generalisierbarkeit und Robustheit.
Datenqualität
Wichtig für die Qualität des mit Deep Learning trainierten Models ist die Verwendung guter Trainingsdaten. Die Daten sollten repräsentativ sein und innerhalb des definierten Bereiches liegen. Auch sollte die Verteilung der Daten so sein, dass das Model realistische Antworten liefern kann. Werden beispielsweise für das Trainieren eines Models für die Spam-E-Mail-Erkennung nur bestimmte Arten von E-Mails verwendet, kann es sein, dass das resultierende Model nicht alle E-Mails entsprechend erkennt.
Auch wenn dieses Problem vor allem bei Verfahren des herkömmlichen Machine Learning auftritt, kann auch beim Deep Learning eine zu einseitige Auswahl an Daten zu schlechten Ergebnissen führen.
Überanpassung, Unteranpassung, Generalisierbarkeit
Eines der Ziele beim Trainieren eines neuronalen networks ist die Generalisierbarkeit des resultierenden Models. Dieses sollte auch für andere Einsatzzwecke bei ähnlichen, bisher unbekannten Daten gute Ergebnisse liefern.
Falls die Qualität der dabei verwendeten Trainingsdaten jedoch zu schlecht oder zu einseitig ist, kann es sein, dass das Model zu stark auf die Trainingsdaten angepasst ist. Bei neuen, vorher unbekannten Daten aus ähnlichen Kontexten liefert es dann schlechte Ergebnisse. Dieses Phänomen wird als Überanpassung bezeichnet.
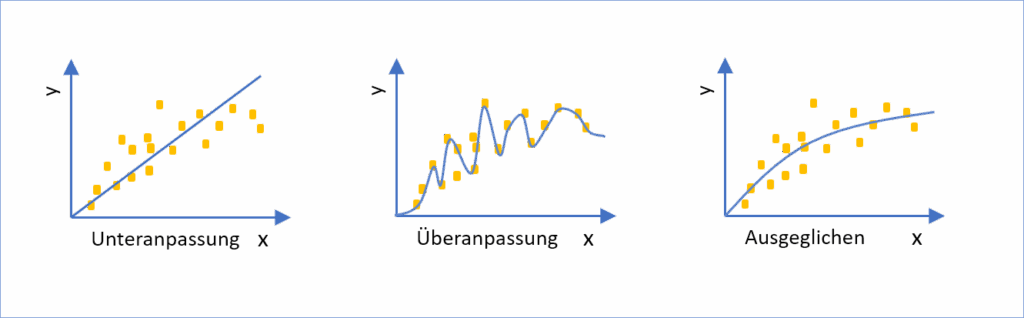
In Anlehnung an: Frauenhofer Gesellschaft – Publikation Maschinelles Lernen
So kann ein Model im Kontext der E-Mail-Erkennung beispielsweise nur mit E-Mails eines bestimmten Formats trainiert worden sein. E-Mails ähnlichen Inhalts, aber mit anderer Formatierung, können von diesem Model dann eventuell nicht mehr zufriedenstellend verarbeitet werden.
Überanpassung wird häufig durch ein zu komplexes neural network verursacht. Bei für Deep Learning verwendeten tiefen neuronalen networks kann die Komplexität z. B. vermindert werden, indem weniger Schichten oder weniger Knoten pro Schicht verwendet werden.
Werden weder Trainingsdaten noch neue Daten zufriedenstellend verarbeitet, spricht man von Unteranpassung. Im Gegensatz zu Überanpassung wird Unteranpassung durch ein zu einfaches network verursacht. Bei tiefen neuronalen networks ist dementsprechend die Anzahl der Schichten oder Knoten zu erhöhen.
Lokale Optima und Schrittweite
Wird z. B. ein Deep Feedforward Network mit Fehlerrückführung trainiert, werden dabei die Gewichte im network schrittweise auf ein Optimum angepasst. Ist diese Schrittweite zu klein, kann es sein, dass die Optimierung in einem sogenannten lokalen Optimum verbleibt, ein anderes, durch stärkere Änderung der Gewichte zu erreichendes Optimum jedoch nicht gefunden wird. Umgekehrt könnte bei zu großer Schrittweite ein Optimum übersprungen und so nicht gefunden werden. Die richtige Wahl der Schrittweite für die Anpassung der Gewichte ist hier entscheidend.
Robustheit
Ist ein durch Deep Learning trainiertes Modell nicht robust, können kleine Änderungen in den analysierten Daten, wie die Formatierung einer E-Mail, zu großen Änderungen in der Ausgabe führen. Robustheit ist ein wichtiger Aspekt hinsichtlich der Verlässlichkeit der Ergbnisse des entsprechenden Modells.
Insgesamt lässt sich feststellen, dass Deep Learning-Modelle auch im Bereich E-Mail-Sicherheit ein breites Anwendungsspektrum haben. Durch die gute Skalierbarkeit solcher Modelle kann z.B. ein Large Language Model eingesetzt werden, um Inhalt und Anhänge von E-Mails hinsichtlich Stil und Bedeutung zu analysieren. Auch können bei genügend großer Datengrundlage eigene Modelle für solche Zwecke trainiert werden.
Weiterhin könnte das Deep Learning-Modell so trainiert werden, dass neben dem Inhalt der Emails auch die Umstände, unter denen sie verschickt werden, z.B. an Feiertagen oder an Tagen, an denen die entsprechenden Mitarbeiter Urlaub haben, mit in das Training einfließen. Auch Auffälligkeiten innerhalb der Infrastruktur des Unternehmens wie auffällige Tasks könnten mit in das Modell integriert werden.
Ziel eines solchen Modells wäre die Erkennung von Auffälligkeiten durch die Verknüpfung möglichst vieler der zur Verfügung stehenden Daten. Dadurch werden eventuell auch Zusammenhänge deutlich, die ein menschlicher Analyst nicht oder nur schwer erkennen kann.
Ziel eines solchen Models wäre die Erkennung von Auffälligkeiten durch die Verknüpfung möglichst vieler der zur Verfügung stehenden Daten. Dadurch werden eventuell auch Zusammenhänge deutlich, die ein menschlicher Analyst nicht oder nur schwer erkennen kann.





{kind=link}