Einführung in Maschinelles Lernen
In den beiden vorhergehenden Blog-Artikeln wurde Methoden und Werkzeuge vorgestellt, mit denen (textuelle) Inhalte untersucht werden können, ob sie von einem Menschen oder einem System, welches auf künstlicher Intelligenz basiert, geschrieben wurden. In diesem Artikel werden nun die verschiedenen Arten des maschinellen Lernens, eine Kategorie der künstlichen Intelligenz, vorgestellt. Zum Beschreiben der Arten des maschinellen Lernens wird die Spam-Analyse von E-Mails beispielhaft verwendet. Es geht somit darum, erkennen zu können, ob eine E-Mail als Spam oder als Nicht-Spam klassifiziert werden kann.
Grundlagen des Maschinellen Lernens
Im Allgemeinen wird beim maschinellen Lernen anhand eines Datensatzes (Trainingsdaten) ein Modell generiert, welches unterscheiden kann, ob eine E-Mail als Spam oder als Nicht-Spam klassifiziert wird. Diese Daten werden als markiert (Spam, Nicht-Spam) bezeichnet. Alle Daten, bei denen keine Klassifizierung vorgenommen wurden, werden als unmarkierte Daten bezeichnet. Je nach Art des maschinellen Lernens, kann der Output, d. h. die Vorhersage oder Erkennung, anschließend bewertet und die Trainingsdaten erweitert werden (vergleiche Abbildung 1). Die Arten des maschinellen Lernens sind das überwachte Lernen, das semi-überwachte Lernen, das unüberwachte Lernen, das bestärkte Lernen und das aktive Lernen.
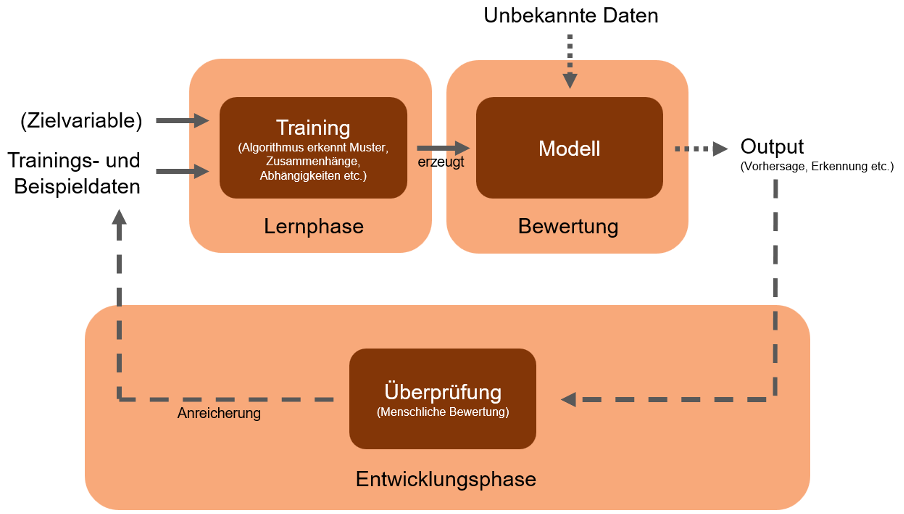
Abbildung 1: Maschinelles Lernen (In Anlehnung an Trabold, D., LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Überwachtes Maschinelles Lernen
Das überwachte Lernen wird meistens für Klassifikationsverfahren verwendet, bei denen das System aus Beispielen lernt. Bezogen auf die Spam-Erkennung sind die vorhandenen E-Mails bereits in den Kategorien „Spam“ und „Kein Spam“ eingeteilt. Bei jeder neu eingehenden E-Mail wird überprüft, ob sie beispielsweise von einer Absender-Adresse kommt oder ein bestimmtes Wort enthält, von denen E-Mails als Spam klassifiziert wurden. Ist dies der Fall wird die E-Mail auch der Kategorie „Spam“ zugeordnet. Entdeckt der Anwender eine E-Mail in einem Postfach, die er als Spam erkennt, kann er diese E-Mail als solche melden und das System kann dadurch weiterlernen. In der Abbildung 2 ist das überwachte Lernen schematisch veranschaulicht.
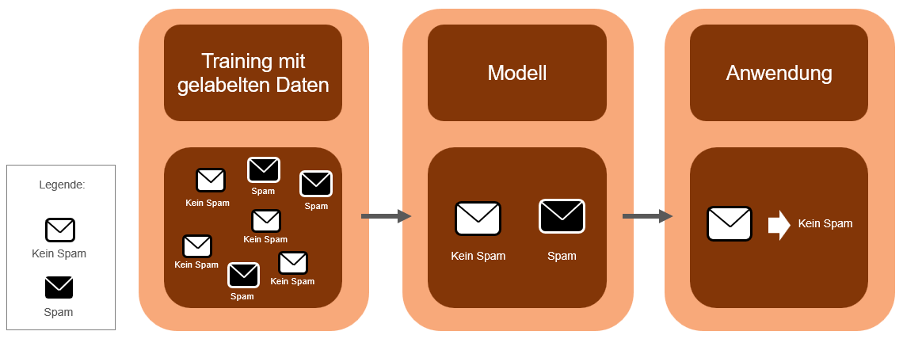
Abbildung 2: Überwachtes Lernen (In Anlehnung an Trabold, D., LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Bestärkendes Maschinelles Lernen
Das bestärkende Lernen ist eine Unterkategorie des überwachten Lernens im Bereich des maschinellen Lernens. Durch Belohnung und Bestrafung lernt der Algorithmus nach und nach, wie er zu handeln hat. Bei der Spam-Erkennung lernt das System durch Interaktion, welche E-Mails als Spam klassifiziert werden sollen und welche nicht, so dass das System eine Bestrafung erhält. Dies passiert basierend auf Belohnungen für eine korrekte oder unkorrekte Klassifizierung. In der Abbildung 3 ist das Vorgehen schematisch veranschaulicht.

Abbildung 3: Bestärkendes Lernen (In Anlehnung an Trabold, D., LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Unüberwachtes Maschinelles Lernen
Beim unüberwachten Lernen versucht das System im Rahmen des maschinellen Lernens, selbständig Muster und Zusammenhänge in Daten erkennen, ohne dabei Beispiele zu haben, an denen es sich orientieren kann. Bezogen auf die Spam-Erkennung können die E-Mails in Cluster eingeteilt werden, die auf ihrer Ähnlichkeit basieren. Das Ziel beim maschinellen Lernen ist es, natürliche Cluster innerhalb der E-Mails zu finden, sodass E-Mails innerhalb eines Clusters ähnlicher zueinander sind als zu E-Mails in anderen Clustern. Bei der Spam-Erkennung können solche Ähnlichkeiten auf verschiedenen Merkmalen wie Textinhalt, Absenderadresse, Anrede, Personennamen, Grußformel, Betreffzeilen, Nutzung von HTML, Links und Anhängen basieren. Beispielsweise können so E-Mails mit einer namenlosen Anrede als Spam klassifiziert werden. E-Mails mit einer Grußformel, in der ein vollständiger Personenname enthalten ist, werden nicht als Spam klassifiziert. Hierfür werden in der Regel sehr große Datenmengen benötigt, um eine Prognose über einen unbekannten Datensatz (E-Mail) zu erstellen.
Genutzt werden kann die Clustering-Methode um neuartige oder sich schnell ändernde Spam-Techniken zu erkennen, für die noch keine markierten Daten zur Verfügung stehen. Schwierig kann es jedoch sein, die Cluster zu bestimmen, insbesondere dann, wenn die Cluster nicht deutlich voneinander abgegrenzt sind. In der Abbildung 4 ist das unüberwachte Lernen veranschaulicht.
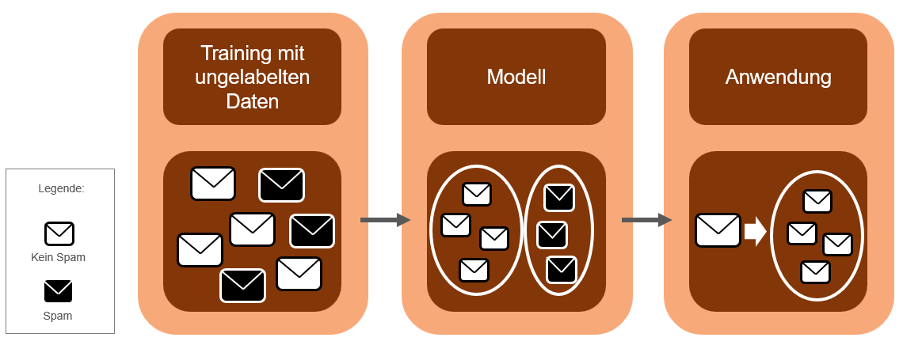
Abbildung 4: Unüberwachtes Lernen (In Anlehnung an Trabold, D., LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Semi-überwachtes Maschinelles Lernen
Eine Kombination aus überwachtem und unüberwachtem Lernen ist das semi-überwachte Lernen, eine weitere Methode im maschinellen Lernen. Hier erfolgt ein Training der Daten mit markierten und unmarkierten Daten. Bei der Spam-Erkennung von E-Mails wird mit dem kleinen Datensatz von markierten E-Mails (Spam oder Nicht-Spam) begonnen. Es wird versucht eine grundlegende Unterscheidungsfähigkeit zwischen Spam- und Nicht-Spam-E-Mails zu erlangen. Nun wird ein neuer unmarkierter Satz von E-Mails in den Trainingsprozess hinzugefügt. Diese neuen E-Mails werden aufgrund der zuvor erlangten Unterscheidungsfähigkeit klassifiziert. Anschließend erfolgt ein Selbsttraining, d.h. die unmarkierten Daten (E-Mails) mit den höchsten Vorhersagewahrscheinlichkeiten werden als richtig angenommen und zu den markierten Daten hinzugefügt. Solange keine zufriedenstellende Genauigkeit des Modells erreicht ist, werden diese Schritte wiederholt. Eine Herausforderung besteht darin, eine sorgfältige Überwachung des Lernprozesses und der Modellleistung zu integrieren. Angewendet wird dieses Verfahren des maschinellen Lernens, wenn das Sammeln umfangreicher markierter Datensätze teuer oder zeitaufwändig ist, aber große Mengen unmarkierter Daten leicht verfügbar sind. In der Abbildung 5 ist das semi-überwachte Lernen veranschaulicht.
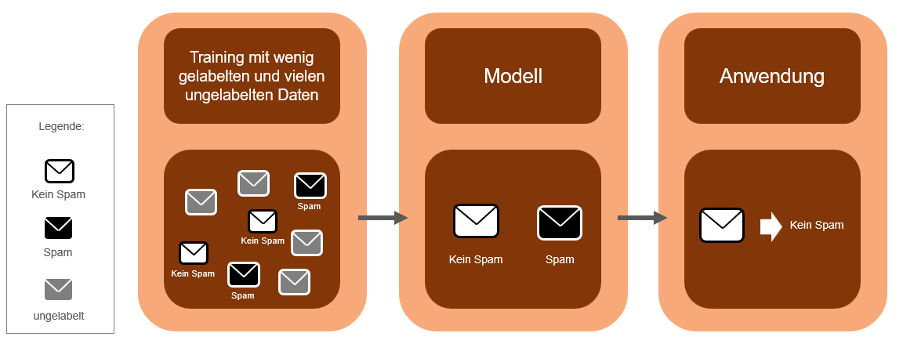
Abbildung 5: Semi-überwachtes Lernen (In Anlehnung an Trabold, D., LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Aktives Maschinelles Lernen
Eine weitere Art des maschinellen Lernens ist das aktive Lernen, bei dem der Algorithmus aus einem Pool zuvor nicht klassifizierter Daten auswählt, welche Teilmenge von Beispielen er als nächstes kennzeichnen will. Der Prozess beginnt mit einem kleinen initialen Set von markierten E-Mail-Daten, die zum Trainieren des Grundmodells verwendet werden. Dieses Modell wird nun auf einen großen Pool von unmarkierten E-Mails angewendet, um diejenigen zu identifizieren, deren Klassifizierung am unsichersten ist. Diese E-Mails werden von einem Experten (z. B. von einem Menschen) als Spam oder Nicht-Spam klassifiziert. Diese neu markierten E-Mails werden dem Trainingsdatensatz hinzugefügt, wodurch das Modell über zusätzliche Informationen verfügt, die es zum Lernen nutzen kann. Dieser Zyklus aus Vorhersage, Auswahl, Markierung und Hinzufügen wird wiederholt, bis eine zufriedenstellende Modellleistung erreicht ist. Das aktive Lernen ist besonders sinnvoll, wenn es nur eine geringe Anzahl an markierten Daten gibt oder es teuer ist, die markierten Daten zu erlangen. Das aktive Lernen wählt gezielt diejenigen unmarkierten Datenpunkte aus, von denen das System glaubt, dass sie die Leistung des maschinellen Lernens am meisten verbessern.

Abbildung 6: Aktives Lernen (In Anlehnung an Beckh, K. LAMARR-Institut für Maschinelles Lernen und Künstliche Intelligenz, 2021)
Eignung des Maschinellen Lernens für die Spam-Erkennung
Welche Methode des maschinellen Lernens angewendet wird, hängt von verschiedenen Faktoren ab. Dazu gehören die Verfügbarkeit markierter Daten, die Dynamik der Spam-Muster und die Ressourcen für das Training und die Wartung der Modelle. Im Allgemeinen liegen bei der Spam-Erkennung große Datenmengen markierter Daten vor. Soll ein System jedoch neu aufgebaut werden und es ist kein Rückgriff auf vorhandene Datensätze möglich, kann es sein, dass nur eine sehr geringe Anzahl von E-Mails klassifiziert sind. Die Spam-Muster sind größtenteils ähnlich, wenngleich immer wieder neue Muster hinzukommen. Die Anforderungen an die Ressourcen für das Training sind normalerweise hoch, da täglich viele neue E-Mails hinzukommen, die bewertet werden müssen. Zusammenfassend lässt sich folgende Eignung im maschinellen Lernen aufführen:
- Überwachtes Lernen: sehr hohe Eignung
Das überwachte Lernen ist für die Spam-Erkennung von E-Mails am besten geeignet. Dieses basiert auf einen großen Datensatz von E-Mails, die bereits als Spam oder Nicht-Spam markiert sind. Eine Stärke des überwachten Lernens ist es, komplexe Muster und Beziehungen in den Daten zu erkennen, was ideal für die Spam-Erkennung ist, da sich diese ständig ändern.
- Semi-überwachtes Lernen: hohe Eignung
Das semi-überwachte Lernen ist insbesondere nützlich, wenn nicht ausreichend markierte Daten zur Verfügung stehen. Dies kommt bei der Spam-Erkennung oftmals vor, da das manuelle Markieren von E-Mails als Spam oder Nicht-Spam aufwendig ist. Durch das Einbeziehen von unmarkierten Daten in den Trainingsprozess, kann das semi-überwachte Lernen effektiver als ein überwachtes Lernen sein, insbesondere wenn sich die Spam-Muster schnell ändern.
- Aktives Lernen: moderate bis hohe Eignung
Das aktive Lernen ist effektiv, wenn die Markierung von Daten teuer und zeitaufwändig ist. Es ermöglicht eine effiziente Nutzung von Ressourcen, indem es gezielt jene Daten für die Markierung auswählt, die den größten Nutzen für das Modell bieten. Daher eignet sich das aktive Lernen insbesondere in dynamischen Umgebungen, wo ständig neue Arten von Spam auftreten, gut für die Spam-Erkennung.
- Unüberwachtes Lernen: moderate Eignung
Mit dem unüberwachten Lernen können unbekannte Muster in E-Mail-Daten erkannt werden, insbesondere wenn keine markierten Daten verfügbar sind. Mit Hilfe von Clustering können neuartige Spam-Techniken identifiziert werden. Im Vergleich zu den überwachten Methoden, kann es schwieriger sein, die Genauigkeit und Zuverlässigkeit der Ergebnisse zu bewerten.
- Bestärktes Lernen: geringe bis moderate Eignung
Das bestärkte Lernen ist komplexer in der Implementierung und Optimierung, da es auf einem Belohnungssystem basiert, um bestimmte Ziele zu erreichen. Beispielsweise um eine Maximierung der korrekten Spam-Erkennung bei Minimierung der Falsch-Positiven zu erreichen.
Deep Learning als Teil des Maschinellen Lernens
Im nächsten Teil der Blog-Reihe über künstliche Intelligenz beim E-Mail-Management wird das Deep Learning (Tiefes Lernen) betrachtet. Das Deep Learning ist eine Lernmethode des maschinellen Lernens, um komplexe Muster in großen Datenmengen zu lernen und zu modellieren. Es kann in allen hier vorgestellten Arten des maschinellen Lernens angewendet werden.